I sidste nyhedsbrev fortalte vi, at skiftet til den open-source-baserede sprogmodel Gemma havde påvirket chatbottens kvalitet. Vi kunne se, at performance var faldet, men vi vidste endnu ikke præcist hvorfor. Var det den nye sprogmodel, der var årsagen? Eller lå forklaringen et andet sted i systemet?
For at finde svaret begyndte vi at skille systemet ad og teste én komponent ad gangen.
Først udskiftede vi selve sprogmodellen og sammenlignede tre forskellige modeller: Gemma (som vi bruger nu), Mistral 3 Large og GLM-4.7, mens resten af systemet forblev uændret. Selvom vi fandt forskelle i kvaliteten og relevansen af svarene, var det ikke nok til at forklare det fald, vi kunne se i den samlede kvalitet. Det tydede på, at problemet ikke primært lå i selve genereringen af svar.
Derefter rettede vi blikket mod en anden del af systemet – den komponent, der arbejder “bag kulisserne” med at finde relevante kilder til chatbotten.
Her opgraderede vi fra en mindre såkaldt embedding-model (multilingual-e5-small) til en større version (multilingual-e5-large), som bruges til at finde og matche jeres spørgsmål med relevante kilder i Lex’ materiale.
Det viste sig at gøre en markant forskel.
På tværs af alle de testede sprogmodeller så vi en tydelig forbedring i vores målinger.
Chatbotten blev ganske enkelt bedre til at finde det rigtige materiale at basere sine svar på – og dermed også bedre til at formulere brugbare svar.
Resultaterne tyder derfor på, at det største problem ikke lå i selve sprogmodellen, men i den måde systemet fandt sine kilder på.
Fald i brugertilfredshed
Figuren nedenfor viser udviklingen i jeres samlede tilfredshed med chatbotten, samthvor ofte den måtte opgive at finde et svar.
Kort efter skiftet til Gemma og den mindre e5-model ser vi et markant fald i tilfredsheden og samtidig en stigning i antallet af afvisninger. Det er altså ikke kun en teknisk måling – det afspejler også den oplevelse, mange af jer i brugerpanelet har delt med os.
Efter opgraderingen til den større e5-model begynder tallene igen at bevæge sig i en mere positiv retning.
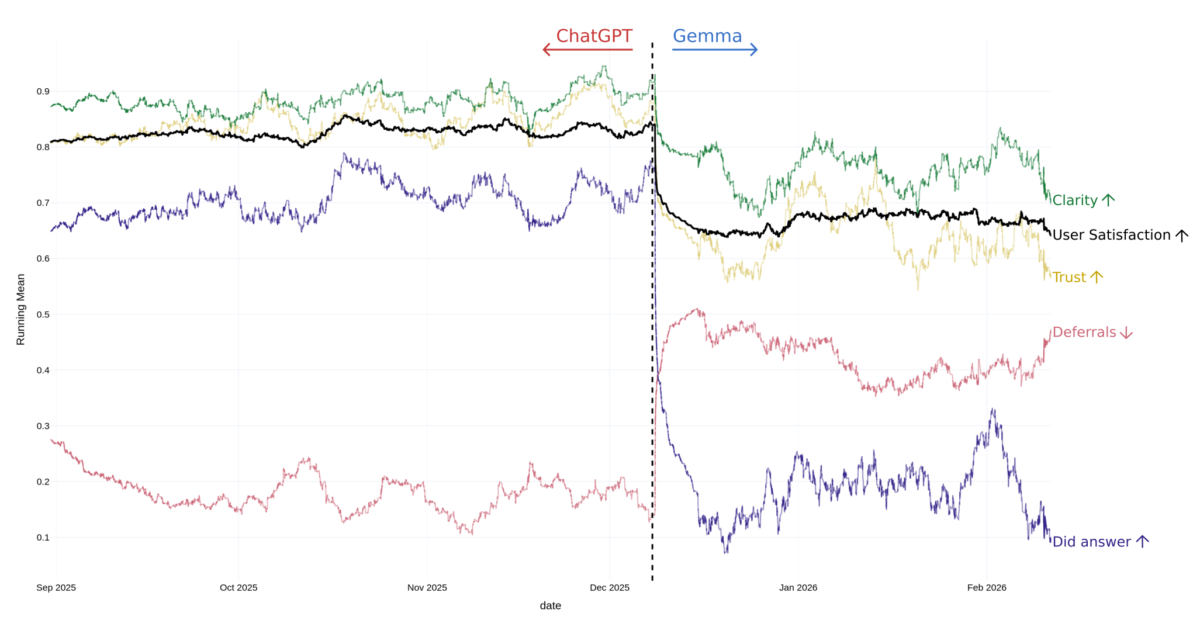
Billedtekst: Efter skiftet til Gemma ser vi et fald i både klarhed (Clarity), brugertilfredshed (User Satisfaction), tillid (Trust), kan ikke svare (Deferrals) og besvarede spørgsmål. (Did answer)
Hvad sker der nu?
Selvom vores tests peger på, at kildesøgningen spillede en større rolle end forventet, betyder det ikke nødvendigvis, at sprogmodellen ikke også skal opgraderes.
Indtil videre har vores evaluering primært målt to ting:
- hvor godt chatbotten holder sig til sine kilder
- hvor godt den faktisk besvarer spørgsmålet
På disse to parametre gjorde større sprogmodeller kun en moderat forskel. Men større modeller kan have andre fordele – for eksempel i forhold til formulering, ræsonnement og håndtering af mere komplekse spørgsmål.
Derfor fortsætter vi også med at teste alternative modeller.